Intelligence artificielle et applications en ophtalmologie

Hugo LE BOITE
Service d'ophtalmologie, Hôpital Lariboisière, Paris

Sophie BONNIN
Service d'ophtalmologie, Hôpital Fondation Adolphe de Rothschild, Paris

Introduction L'intelligence artificielle est définie comme l'intelligence des machines, par opposition à l'intelligence naturelle, celle des êtres vivants[1]. Elle correspond à l'utilisation d'agents intelligents, capables de percevoir l'environnement (input) et de prendre des décisions rationnelles (algorithme) permettant de maximiser les chances d'atteindre un objectif (output).
Au sein de ce domaine, l'apprentissage machine (machine learning) est une sous-catégorie désignant des algorithmes dont les compétences vont s'améliorer avec l'expérience (entrainement). Ainsi, plus la quantité de données disponibles pour l'entrainement est importante, plus les performances de l'algorithme vont s'améliorer. On divise habituellement les problématiques de machine learning en plusieurs catégories [2]. Ainsi, en premier lieu, dans une approche d'entrainement supervisé, on donne les réponses attendues au modèle au cours de l'entrainement : il s'agit premièrement des taches de régression, où l'on cherche à prédire la valeur d'une variable en fonction d'autres variables. Un exemple simple est l'application d'une régression linéaire sur un ensemble de données cliniques pour prédire la durée d'hospitalisation d'un patient dans un service. Une deuxième catégorie de problème supervisé correspond à la classification. Une image en entrée doit être classée dans une des catégories disponibles. On peut par exemple classer une radiographie thoracique comme normale ou pathologique. Ensuite, dans une approche définie comme non supervisée, des problèmes de réduction de dimension (analyse en composante principale par exemple, qui permet une représentation graphique simple d'un ensemble de nombreuses variables) ou des problèmes de clustering sont résolus. Le clustering a pour but de rassembler des individus en groupes (ou clusters) en fonction de leur proximité par rapport à un ensemble de variables : on peut par exemple tenter de définir des groupes de patients en fonction de leur profil génétique. Dans cette approche, il n'y a pas de réponse connue, ou d'attribution a priori de groupe pour les individus, d'où le terme de non supervisé. Le modèle peut définir seul les groupes et le nombre de groupes.
Une autre sous-catégorie du machine learning est l'apprentissage profond (deep learning), qui correspond à l'utilisation de modèles particuliers, appelés réseaux de neurones, dont l'architecture est inspirée du fonctionnement du cerveau humain, et qui répondent à des problématiques de régression ou de classification (le plus souvent supervisé) de manière particulièrement puissante [3]. Un réseau de neurones est constitué d'une ou plusieurs couches de neurones, chaque neurone étant simplement la matérialisation d'une fonction mathématique, prenant en entrée des valeurs provenant d'autres neurones qui lui sont connectés, et produisant en sortie une certaine valeur (correspondant à son activation). L'application de plusieurs couches de neurones permet mathématiquement de répondre à des problèmes non linéaires, là où les modèles de régression classique sont limités. Mais dans l'analyse d'image, cette architecture particulière permet également l'extraction automatique d'éléments de complexité variée au sein de l'image (feature extraction), sans avoir besoin de définir ces éléments a priori. Ainsi, pour reconnaître un chat, il n'est plus nécessaire de définir ce qu'est une oreille, des pattes ou des moustaches, puisque le modèle définit lui-même les éléments qui lui permettent de répondre le mieux à la question posée. Les différentes couches du réseau vont extraire des éléments de complexité croissante, allant de la détection d'un bord à la détection d'un visage par exemple. Imaginés en 1978 par G. Hinton, mis en place pour la première fois pour la vision par ordinateur par Y. Le Cun en 1989 pour la lecture automatique du code postal sur les lettres aux États-Unis [4], ces modèles voient leur utilisation exploser en 2012 quand l'utilisation d'un réseau de neurones convolutifs combiné à une carte graphique puissante (GPU) permet à A. Krizhevsky [5] de remporter le challenge de classification ImageNet. En raison de la présence en ophtalmologie de nombreux examens complémentaires d'imagerie, le recours à des modèles d'intelligence artificielle serait particulièrement utile. On pourrait ainsi appliquer ces méthodes à de nombreuses problématiques, comme la prédiction de l'apparition de maladie (régression), le diagnostic automatique en imagerie (classification), l'analyse pixel par pixel d'une image pour la segmentation d'une zone pathologique (tâche de segmentation, sous-catégorie d'un problème de classification). Le but de ces utilisations serait d'avoir un outil d'aide à la décision, un outil d'analyse automatique d'image, ou encore un outil de prédiction de l'évolution, qui pourrait faciliter le travail médical en pratique clinique.
Applications en ophtalmologie
Nous proposons ici quelques exemples d'applications d'intelligence artificielle dans différents domaines de l'ophtalmologie.
Le dépistage de la rétinopathie diabétique par rétinophotographies est un problème auquel se sont attaquées plusieurs équipes, comme le décrivent de nombreuses publications montrant la faisabilité théorique de type de dépistage. L'entreprise anglaise EyeNuk a par exemple développé EyeArt (https://www.eyenuk.com/en/products/eyeart/) qui donne en 1 minute un diagnostic de dépistage de la rétinopathie diabétique. L'entreprise américaine Digital Diagnostics a développé IDxDR (https://www.digitaldiagnostics.com/products/eye-disease/idx-dr/). Google a développé en partenariat avec l'hôpital ophtalmologique d'Aravind en Inde Google Verily Life Science. Une entreprise française a également développé OphtAI (Evolucare et ADCIS), en partenariat avec P. Massin et B. Cochener, qui donne un diagnostic de rétinopathie diabétique en quelques secondes. Ces outils, ainsi que d'autres travaux [6], montrent que les performances diagnostiques sont très bonnes et proches des capacités diagnostiques d'un ophtalmologiste en pratique clinique (aire sous la courbe ROC de 0.99, sensibilité supérieure à 0.9, sensibilité autour de 0.85 pour la plupart des modèles). L'équipe de G. Quellec, qui a notamment travaillé sur le projet OphtAI, a également élargi la capacité diagnostique du modèle à la détection de n'importe quelle anomalie au fond d'œil [7], et non plus seulement le dépistage de la rétinopathie diabétique. L'aire sous la courbe pour le dépistage d'anomalie en population générale est de 0.9108, et la comparaison à un ophtalmologiste montre que le modèle est plus performant (pour une spécificité de 0.86, la sensibilité du modèle est de 0.82 contre 0.67 pour le médecin). Une autre tâche particulière complexe et chronophage est l'analyse des images d'OCT obtenues en pratique courante pour le diagnostic et le suivi de pathologies rétiniennes variées. Dans cette thématique, de très nombreux travaux ont été publiés, mais le plus marquant reste la production par le laboratoire DeepMind de Google, en partenariat avec le Moorfields Eye Hospital (Londres), d'un modèle combinant dans un premier module des capacités de segmentation automatique des couches rétiniennes et des zones pathologiques (liquide intra rétinien, liquide sous rétinien, décollement de l'épithélium pigmentaire, exemple dans la figure 1), mais également dans un deuxième module des capacités de prédiction du diagnostic parmi 50 pathologies différentes, combinées à une indication de prise en charge (évaluation du degré d'urgence). Entrainé sur 877 images annotées pour le premier module et 14 884 cartes de segmentation avec diagnostic pour le deuxième module, ce modèle obtient en utilisant seulement l'image OCT un taux d'erreur de 5,5 % dans l'évaluation de l'urgence, soit mieux que le meilleur des 4 experts rétinologues, ou aussi bien que le meilleur expert quand celui-ci avait en plus de l'OCT des images du fond d'œil et des informations cliniques [8]. Enfin, dans le domaine de la prédiction de l'évolution, on peut citer l'étude en cours EVIRED, RHU national centralisé à l'hôpital Lariboisière sous la direction du Pr Tadayoni, qui a pour but la création d'un modèle de deep learning capable de prédire le risque d'évolution vers une rétinopathie diabétique proliférante chez des patients diabétiques, en utilisant comme paramètres d'entrée les images du fond d'œil, les images d'OCT ainsi que des images d'OCT-Angiographie et quelques paramètres cliniques. Plusieurs éléments sont intéressants : d'abord, obtenir un outil précis de prédiction dans un contexte particulièrement multifactoriel qu'est la rétinopathie diabétique et son évolution, mais aussi comprendre les éléments pris en compte par le modèle pour la prédiction, ce qui permettrait de mieux comprendre les facteurs cliniques et biologiques qui sont réellement prédictifs d'une évolution péjorative. Dans les problématiques liées au glaucome, plusieurs équipes [9, 10] ont tenté de construire des modèles capables de prédire le risque de glaucome en fonction de l'aspect de la papille au fond d'œil (rétinophotographies). Une autre équipe [11] a développé un modèle capable de reconnaître l'atteinte glaucomateuse de l'OCT RNFL, comparée aux autres causes d'atteintes du RNFL. Utilisant un modèle avec entrainement non supervisé, des équipes ont également pu détecter une atteinte cliniquement significative du champ visuel chez des patients suivis pour glaucome[12, 13]. Dans une approche plus globale, un modèle prédisant l'évolution de la maladie glaucomateuse en utilisant en entrée la pression intraoculaire et les résultats de champ visuel, a été développé[14]. De très nombreuses autres applications de l'IA ont été montrées, comme par exemple le dépistage de la rétinopathie du prématuré [15] : le modèle développé détecte la forme « plus » de la pathologie, avec une aire sous la courbe de 0.98 par rapport au diagnostic obtenu par consensus [15]. On trouve également des applications dans le diagnostic et la prise en charge des maladies rétiniennes héréditaires [16], du diagnostic et de la prédiction des récidives du ptérygion [17] ou encore de l'amélioration de la qualité des mesures d'autoréfractométrie portative [18].
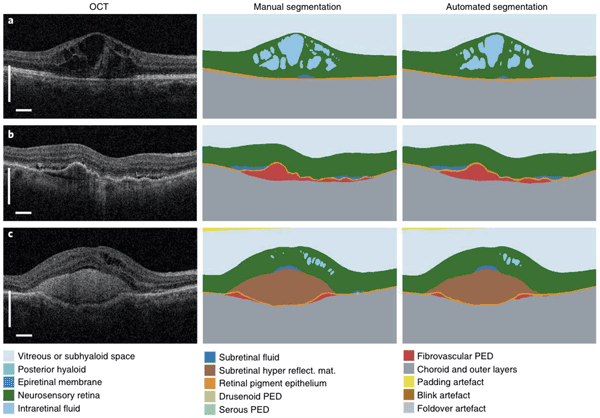
Figure 1 Illustration des capacités de segmentation du modèle [8]
Conclusion L'utilisation des modèles d'intelligence artificielle, et notamment de deep learning, permet de répondre efficacement à de très nombreux problèmes, souvent avec une précision et une pertinence proche de l'opérateur humain. Les limites sont actuellement de plusieurs ordres : d'abord, l'entrainement d'un réseau de neurones, pour répondre à une question précise, nécessite une quantité très importante de données (plusieurs centaines d'images pour une tache de segmentation mais plusieurs milliers d'images pour une tache de classification, et plusieurs millions pour des taches complexes de traitement du langage naturel). Ensuite, ces modèles sont particulièrement coûteux en énergie, pour l'entrainement, mais également pour la prédiction. Enfin, chaque modèle, à l'heure actuelle, est le plus souvent entrainé pour une tache précise. Ainsi, un modèle qui dépiste la rétinopathie diabétique au fond d'œil (absence ou présence), ne peut pas être directement utilisé pour prédire la normalité du fond d'œil, ou la présence d'une autre pathologie. Il faut ré-entrainer le modèle avec la nouvelle question et les nouvelles réponses attendues. De même, les taches de segmentations sont particulièrement sensibles au format de l'image, ainsi que l'intensité lumineuse des images. Ainsi, un modèle de segmentation de l'œdème intra rétinien développé sur des images issues d'un OCT Cirrus (Zeiss®), même très performant, ne fonctionnera pas de manière correcte sur des images issues d'un OCT Spectralis (Heidelberg®). Il faudra de nouveau entrainer le modèle en incluant des images d'autres machines dans le jeu de données. Ceci est illustré dans la figure 2. Cette limite correspond au concept de biais en intelligence artificielle. Le modèle apprend en fonction des données qu'on lui montre, et va reproduire les biais de la base d'entrainement. Si celle-ci n'est pas représentative de la population cible dans le monde réel, le modèle risque de fonctionner de manière dégradée. Ainsi, certains algorithmes de reconnaissance faciale entrainés principalement sur des bases de données de personnes d'origine caucasienne, fonctionnent très mal sur des populations afro-américaines, et mènent à des arrestations erronées. Le biais en intelligence artificielle est une thématique de recherche qui se développe, pour obtenir un transfert du concept d'éthique vers ce domaine en expansion. Une autre limite est celle de l'effet black-box. Le fonctionnement interne d'un réseau de neurones est particulièrement difficile à comprendre et visualiser, et les choix du modèle peuvent donc rencontrer une forme de suspicion de la part des utilisateurs, et crée un frein à son emploi. Pour remédier à ce problème, l'utilisation de carte de visualisation permet par exemple de voir quelles zones de l'image un modèle a utilisé pour faire son choix de pathologie, dans une tâche de classification. Finalement, nous sommes actuellement en médecine encore très loin du concept d'artificial general intelligence, où la machine serait capable de manière autonome de diagnostiquer et recommander une prise en charge pour une multitude de pathologies et une multitude d'examens. Une limite supplémentaire en pratique est que même si de nombreux travaux montrent la puissance d'outil d'intelligence artificielle en médecine, il y a, à l'heure actuelle, encore peu d'outils validés et utilisables en pratique clinique. La majorité des travaux d'intelligence artificielle en médecine et notamment en ophtalmologie sont actuellement des travaux de recherche scientifique. Les outils d'intelligence vont continuer à prendre une place de plus en plus importante au sein des outils de la médecine moderne, comme le montre le rapport 2022 de Stanford Institute for Human-Centered Artificial Intelligence (HAI) [19], qui indique que les investissements privés dans le domaine de l'IA sont passés de 45 milliards de dollars en 2020 à 94 milliards en 2020 (un chiffre inférieur à 10 milliards avant 2016) et que les publications scientifiques en rapport avec l'IA étaient en 2021 au nombre de 334 500, contre 150 000 en 2010.
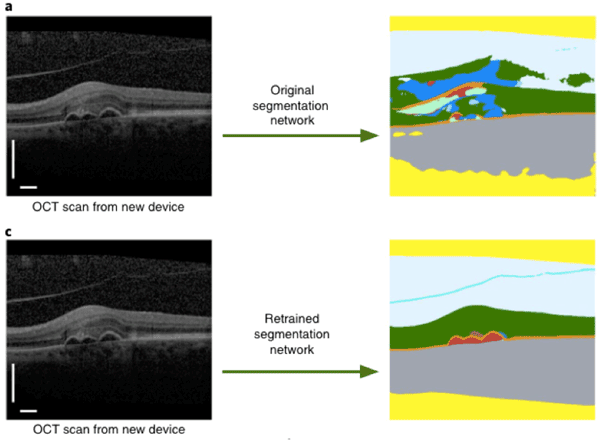
Figure 2 Illustration adaptée de [8], montrant en a. les performances d'un modèle entrainé sur un appareil et utilisé sur un autre appareil d'OCT. En c., on voit les performances du modèle une fois l'entrainement fait sur une base de données avec des images issues du même appareil.
RETOUR SOMMAIRE